
AI 서비스
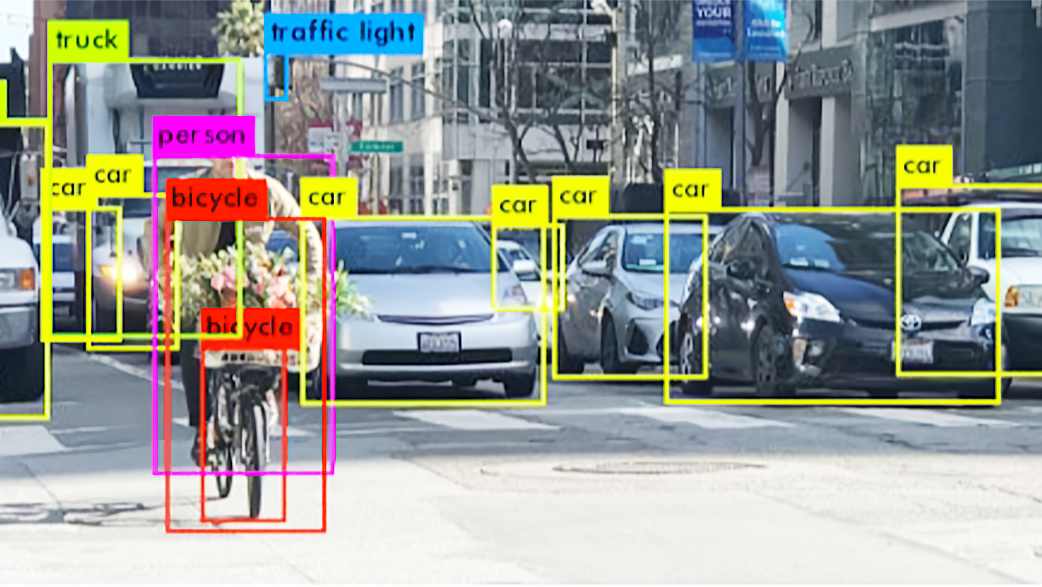
01. Object Detection (객체 탐지)
아래 그림에서 보듯이 각각의 Objcet가 무엇인지를 감지하는
비전 A.I. 기술을 의미함.
비전 A.I. 초기 모델로 카메라에 보이는 사물을 구분하는 기술
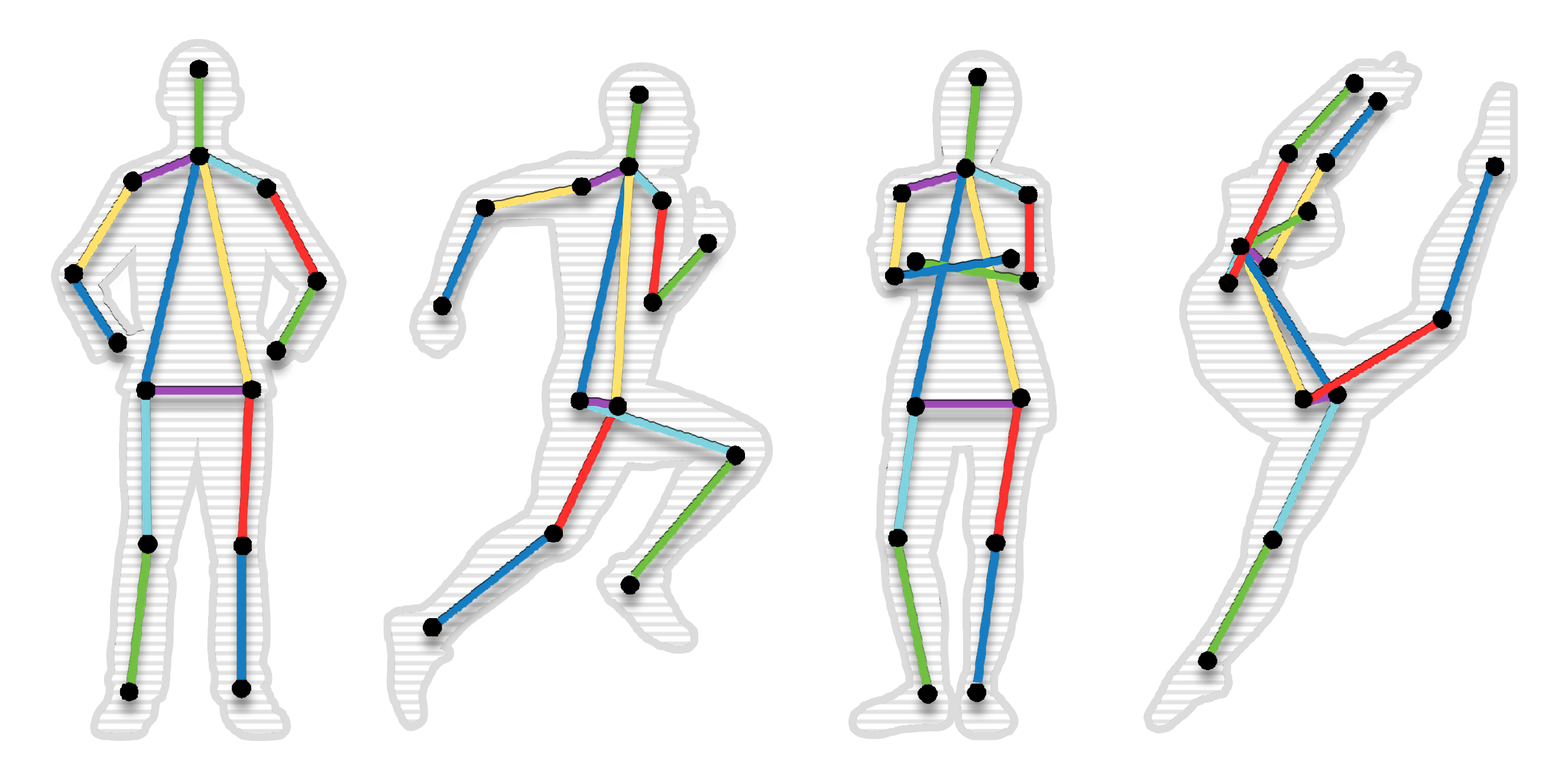
02. POSE ESTIMATION (자세추정)
Object Detection을 통해 사람을 인지 한 후에
사람의 행동을 분석하고자 하는 필요에 의해 사람의 관절을
Key-point로 하여 관절의 움직임으로 사람의 행동을 분석
하기 위하여 개발한 비전 A.I. 알고리즘으로 자세를 분류하는
것 까지만 가능함.
03. CNN 모델
(Convolutional Neural Network, 합성 곱 신경망)
주로 이미지를 처리하는데 사용함.
픽셀로 대상(Object)을 인지하고 분류함 (정교해졌으나,
대규모 연산처리장치가 필요함)
이미지나 비디오같은 영상인식에 특화된 설계로, 이전까지는
평면적인 이미지 분석만 가능했으나, 효과적으로 공간을
기반으로 영상분석이 가능하게 하였음.
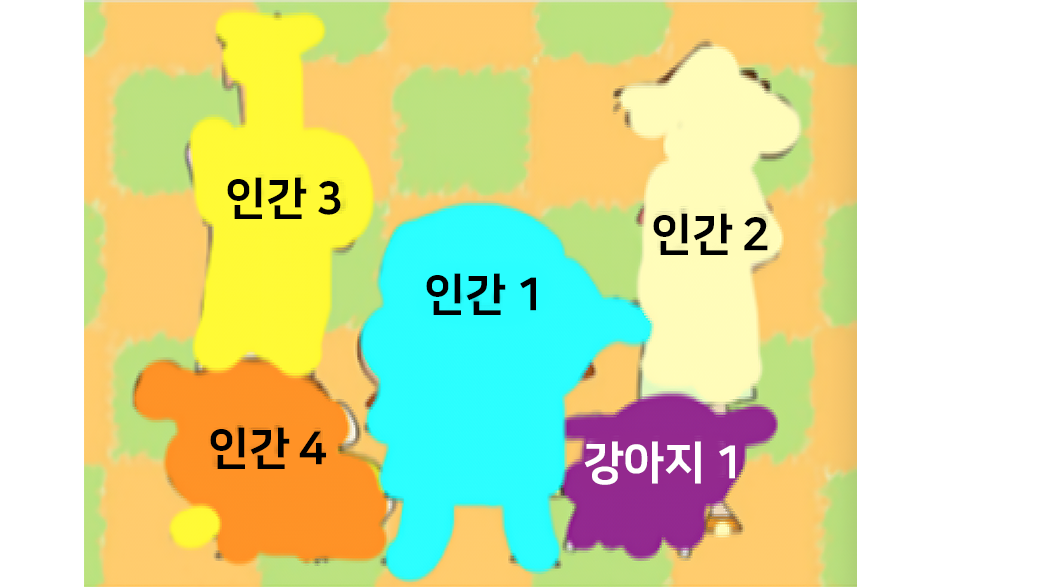
04. MASK R CNN 모델
이미지 내에 존재하는 모든 객체를 탐지(Obcjet Detectio
n)하는 동시에 각각의 경우(Instance)를 정확하게 픽셀
단위로 분류하여 인식함 (Semantic Segmentation).
모든 객체를 탐지하는 동시에 각각의 경우(Instance)를
정확하게 픽셀 단위로 분류(Class)하는 Task로서 기존의
다른 인공지능 알고리즘들 보다 속도와 정확성에서 높은
성능을 보였음.
05. Quantum view 모델
아래 영상에서 보듯이 사람의 행동 분석을 가능하게 한 모델로 사람의 이상행동을 추론 할 수 있으며 (Action Recognition) 사람의 이상행동에 대한 정확도 및 연산속도를 높였음.

사람탐지
(객체 탐지, Object Detection)
사람의 관절 좌표 인식
(자세추정, Pose Estimation)
이상행동 탐지
(행동인식, Action Recognition)
5-1. 주간에 사무실에서 실신하는 사람을 AI가 정확히 분석하는 영상.
사무실에서 실신해서 쓰러지는 사람을 인공지능이 정확히 분석해 내는 영상으로 사람의 탐지 시 네모박스(Boundin Box)가 사람을 탐지(객체탐지-Object Detection)하고, 사람의 관절포인트 17개를 정확히 포착한 후(자세추정-Pose Estimation), 실신시에 동시에 한번의 분석(행동인식-Action Recognition)으로 사람의 행동을 분석함.
야간에 집안에서 낙상을 당하는 사람을 인공지능이 정확히 분석해 내는 영상으로 사람의 탐지 시 네모박스(Boundin Box)가 사람을 탐지(객체탐지-Object Detection)하고, 사람의 관절포인트 17개를 정확히 포착한 후(자세추정-Pose Estimation), 낙상시에 동시에 한번의 분석(행동인식-Action Recognition)으로 사람의 행동을 분석함.
폭력행위를 당하여 쓰러지는 사람을 인공지능이 정확히 분석해 내는 영상으로 사람의 탐지 시 네모박스(Boundin Box)가 사람을 탐지(객체탐지-Object Detection)하고, 사람의 관절포인트 17개를 정확히 포착한 후(자세추정-Pose Estimation), 낙상시에 동시에 한번의 분석(행동인식-Action Recognition)으로 사람의 행동을 분석함.
-
5-4. CCTV 영상을 행동인식 인공지능 퀀텀뷰로 분석한 영상.